The USI project has been initiated at the LGI2P research center during the PhD of Nicolas Fiorini. The main motivation behind this work is to provide a kNN-based approach for annotating entities, be it textual documents, songs or movies. While other methods often combine machine learning and feature analysis of a given document (e.g. textual features), USI's approach is completely independent of the document content. The only requirement in order to guarantee an accurate annotation is to provide an accurate already annotated neighborhood. The search of a good neighborhood is an independent task, related to information retrieval, for which an extensive list of tools already exist.
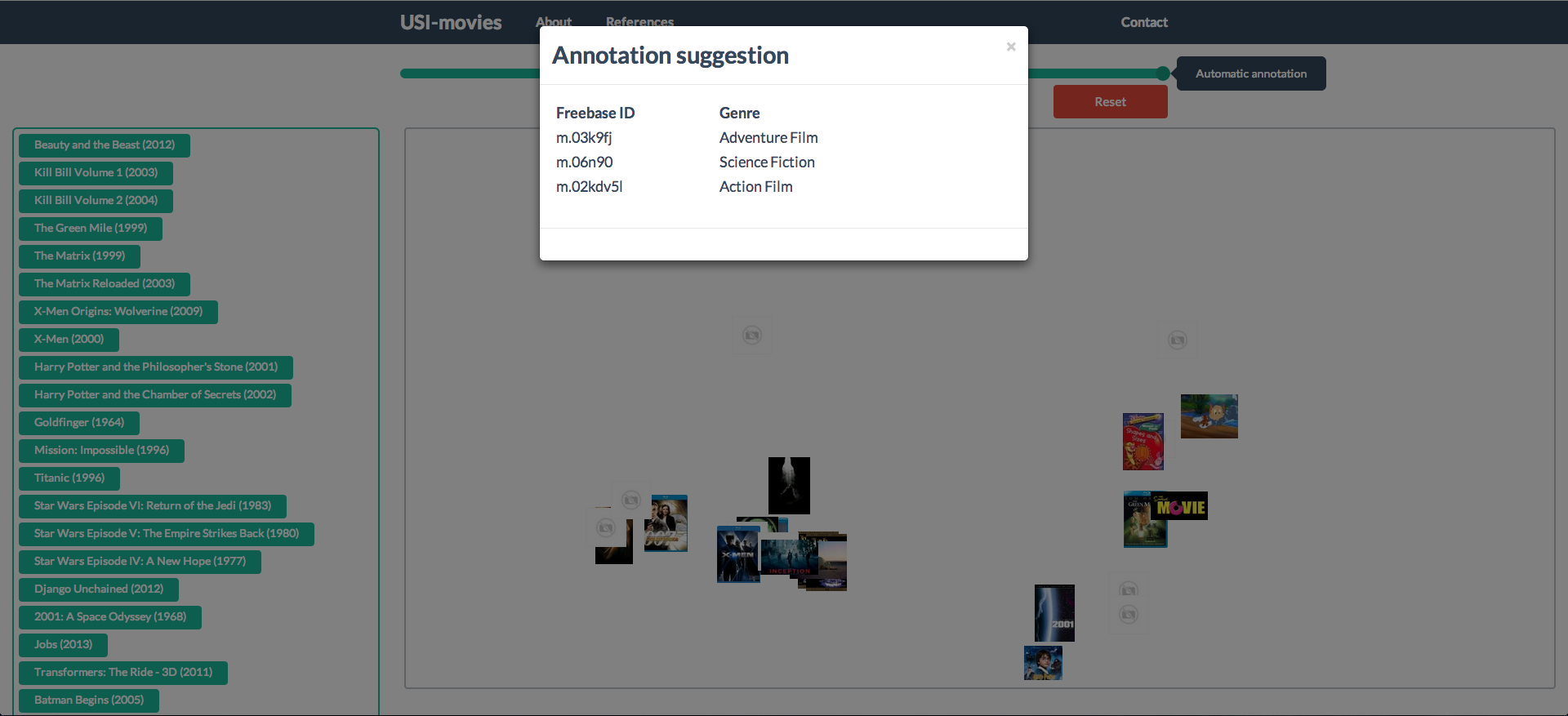
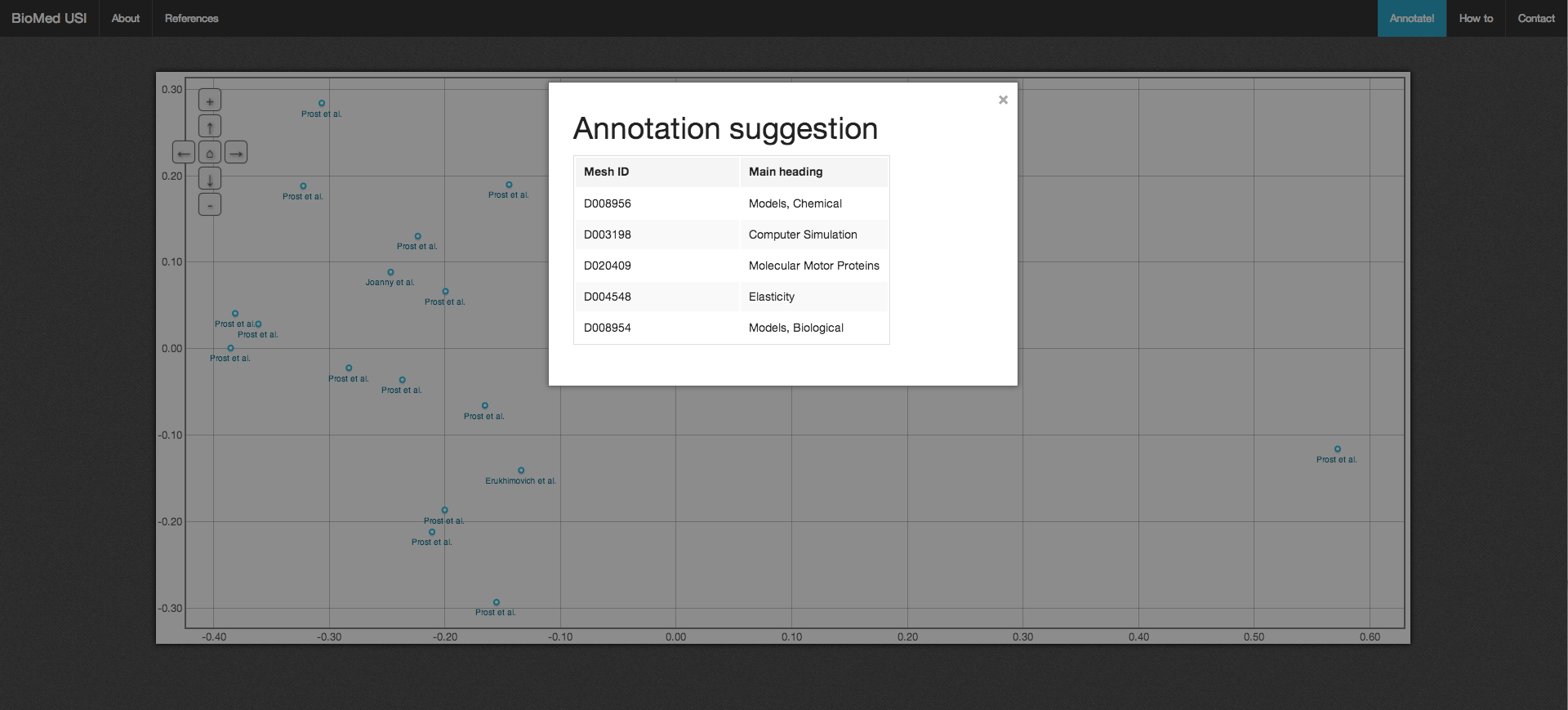
With the rise of thesauri, ontologies and knowledge representations in general, there are more and more data that can be annotated by concepts. The semantic indexing process has been initiated in the biomedicine field but much more content can now benefit from conceptual indexing using DBPedia or Freebase. USI aims to do so, whatever is the content, whatever is the thesaurus, all thanks to the very useful Semantic Measures Library to compute semantic similarities between concepts.
USI is presented as a heuristic algorithm optimizing an objective function. We propose an algorithmic optimization of this heuristic to make it fast enough, implemented in the USI java library. This library is also hosted on GitHub and it can be freely downloaded to be implemented in your project.